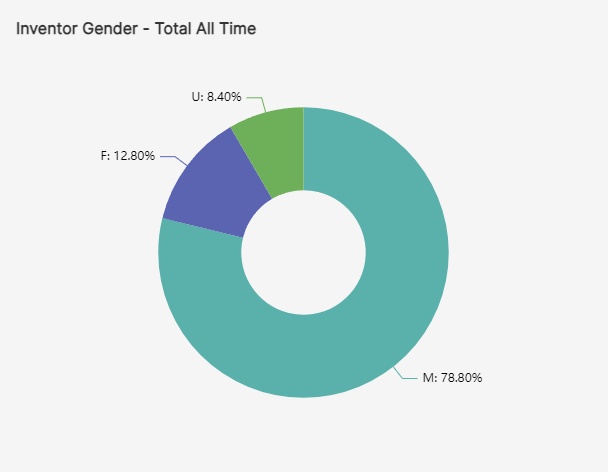
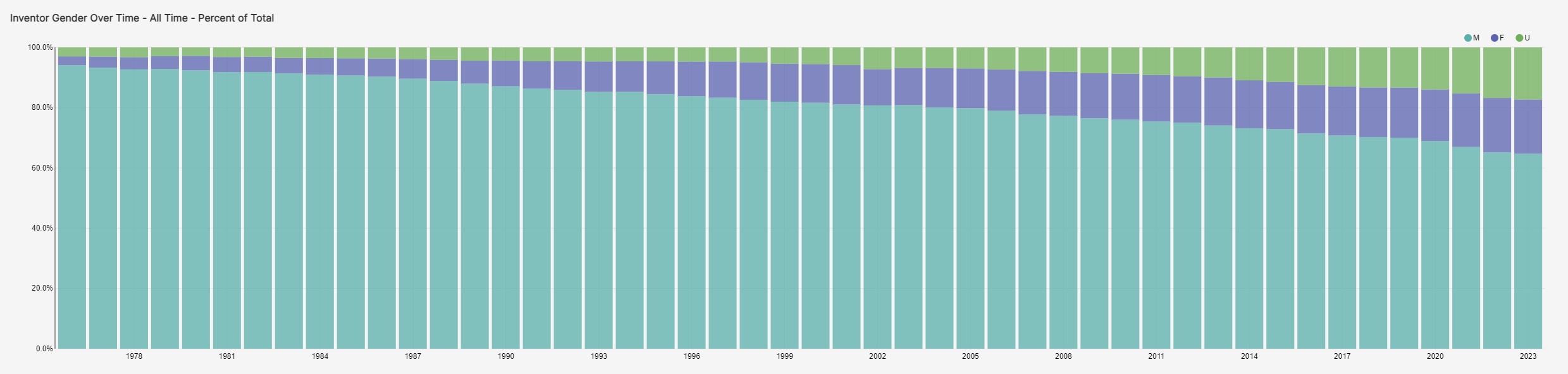
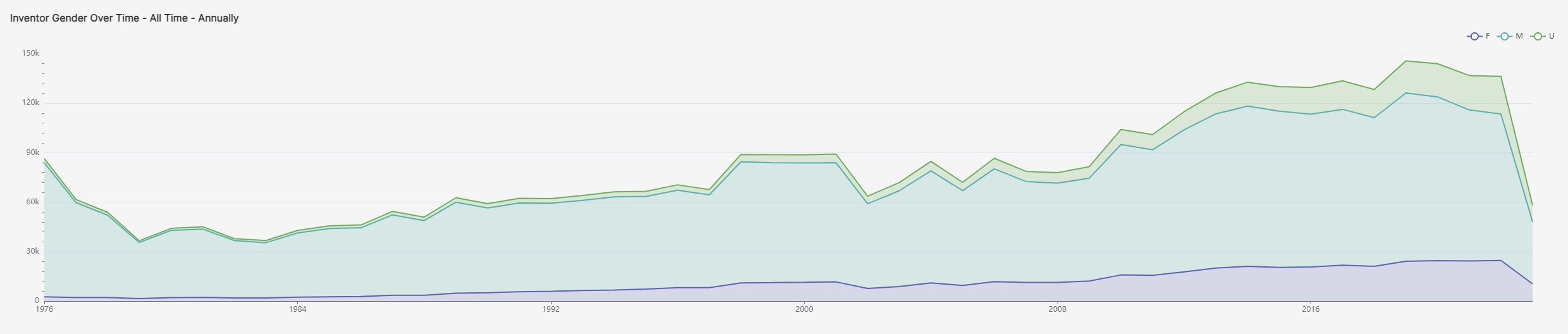
by Pablo Galaso and Sergio Palomeque
Patent data have been extensively used in academic research in several knowledge areas. This kind of data is particularly useful for studying knowledge flows and factors affecting innovation. In this sense, detailed information on inventions registered by patents and the possibility of studying the interactions between agents are among their main advantages.
In Latin America, academic research using this type of data is limited compared to other parts of the world, due to the absence of an international office that allows comparability between countries by unifying the patent regulatory framework. In addition, historically, patent offices worldwide have ensured the identification of each registration but, for various reasons, not unique identifiers to the actors involved.
PatentsView Helps Fill in Gaps in Patents Data for Researchers
To address these difficulties, researchers at the Institute of Economics of the UdelaR have used the data provided by PatentsView to carry out academic research since 2017. This research contributes to understanding the characteristics and limitations of innovation systems in Latin America, at regional, national and subnational levels (https://spwebfcea.wixsite.com/inventioninla).
The relevance of obtaining intellectual property protection in the United States for frontier innovations makes the USPTO records useful for analysing innovation processes in different regions of the world, particularly in Latin America, where there is no international agency. The use of USPTO data allows an adequate comparison of inventive activities between countries, avoiding problems associated with the institutional differences among national patent offices.
On the other hand, the process of systematising information and disambiguating actors carried out by PatentsView allows the use of patent data on a much larger scale than in the past.
In-depth Learning and Applications
To support and disseminate the use of this data, we have conducted a series of activities, including:
A webinar that sought to:
- Introduce participants to the advantages of using USPTO patent data for research on collaboration networks in cities and regions of developing countries, especially in Latin America. The webinar presented the main features of this data source, the advantages of accessing it through the PatentsView platform and some examples of research articles using this data.
A workshop where:
- The participants learned more in-depth about the applications and methods that use this data and practiced how to use R for processing and analysis of collaboration networks.
These activities were carried out within the Regional Studies Association Research Network on Knowledge, Innovation and Regional Development in South America (KIRDSA).
Further Reading
Below is a list of papers we have published in this line of research, which may provide a better idea of the possibilities for Latin America and other world regions.
- Bianchi, C., Galaso, P., & Palomeque, S. (forthcoming). Absorptive capacities and external openness in underdeveloped Innovation Systems: A patent network analysis for Latin American countries 1970-2017. Cambridge Journal of Economics. https://doi.org/https://doi.org/10.1093/cje/bead034
- Bianchi, C., Galaso, P., & Palomeque, S. (2023). Knowledge complexity and brokerage in inter-city networks. The Journal of Technology Transfer. https://doi.org/10.1007/s10961-023-10025-x
- Bianchi, C., Galaso, P., & Palomeque, S. (2023). The trade-offs of brokerage in inter-city innovation networks. Regional Studies, 57(2), 225–238. https://doi.org/10.1080/00343404.2021.1973664
- Bianchi, C., Galaso, P., & Palomeque, S. (2021). Patent Collaboration Networks in Latin America: Extra-regional Orientation and Core-Periphery Structure. Journal of Scientometric Research, 10(1s), s59–s70. https://doi.org/10.5530/jscires.10.1s.22
- Bianchi, C., Galaso, P., & Palomeque, S. (2020). Invention and Collaboration Networks in Latin America: Evidence from Patent Data (DT 04/2020). Serie Documentos de Trabajo. Montevideo.
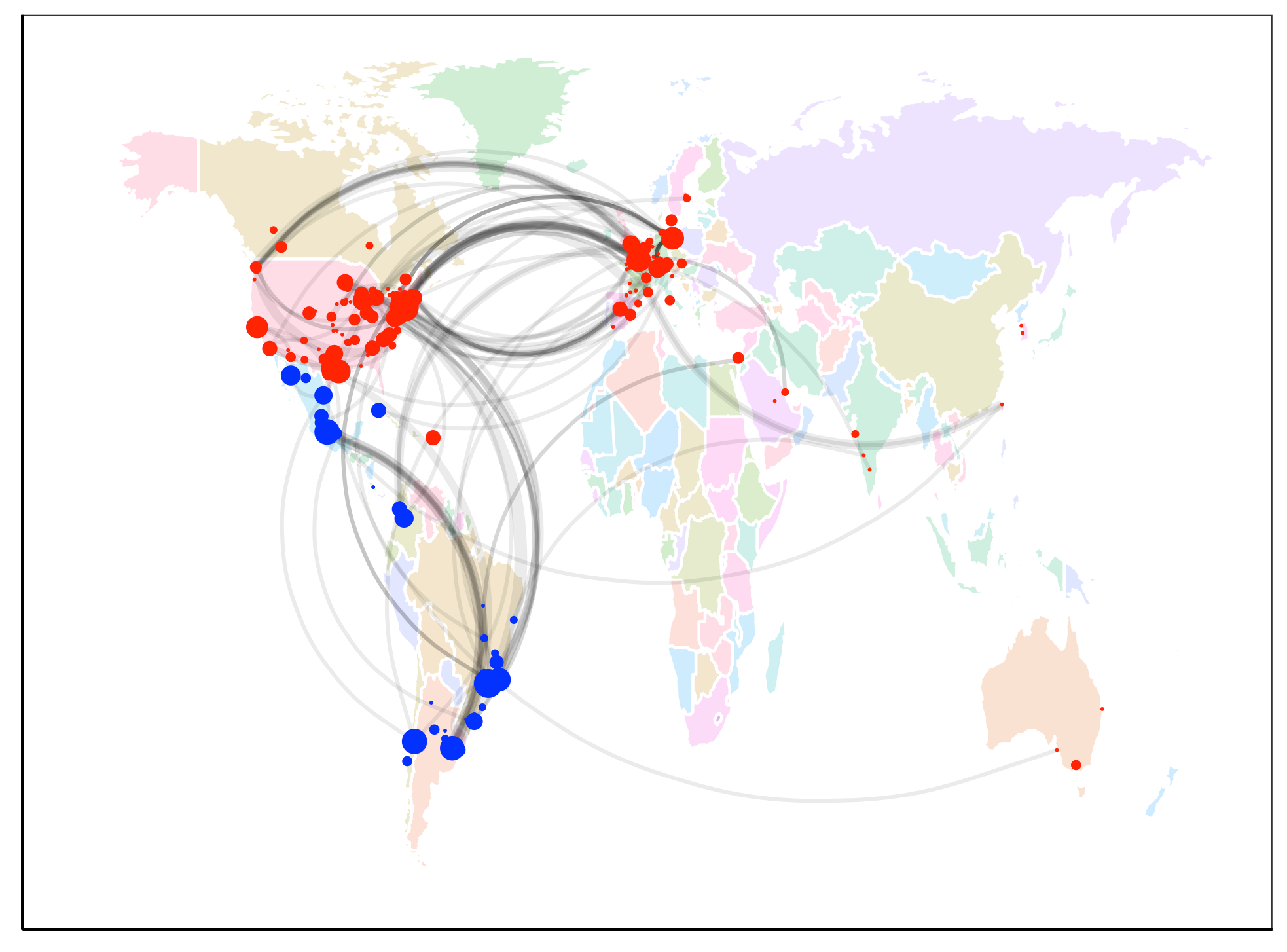
Inter-city collaboration network in Latin America